2026-03-09
llmfit:根据硬件自动匹配最佳LLM模型的神器
前言
想本地运行大语言模型,但不知道自己的电脑能跑哪些模型?选了模型又纠结用什么量化级别?llmfit 就是来解决这个问题的。
它是一个命令行工具,能自动检测你的 CPU、内存、GPU 配置,然后从数百个模型中筛选出最适合你硬件的选择,还会告诉你用哪个量化级别效果最好。
安装
macOS / Linux 一键安装:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh
Homebrew:
brew tap alexsjones/llmfit
brew install llmfit
Windows:
可以通过 Scoop 安装。
使用方法
TUI 交互模式(默认)
直接运行 llmfit 会启动一个漂亮的终端界面:
- 顶部显示你的系统配置(CPU、RAM、GPU、VRAM 等)
- 列出所有模型,按综合评分排序
- 每行显示评分、预估速度、最佳量化、运行模式、内存占用等
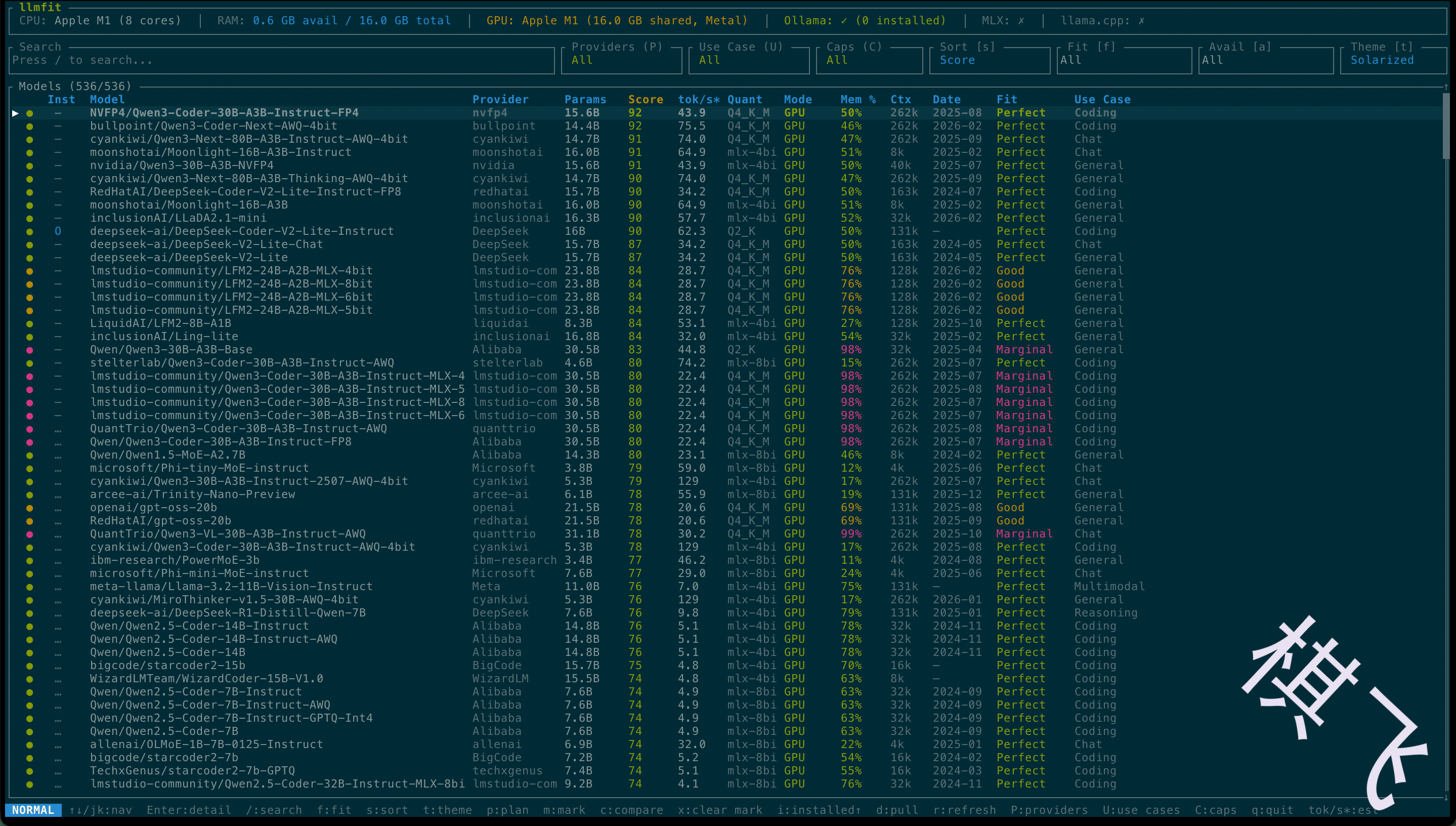
常用快捷键:
| 按键 | 功能 |
|---|---|
j/k 或 ↑/↓ |
上下导航 |
/ |
搜索模式 |
f |
筛选适配等级(全部/可运行/完美/良好/勉强) |
d |
下载选中模型 |
p |
硬件规划模式(查看运行该模型需要什么配置) |
t |
切换主题 |
Enter |
查看详情 |
q |
退出 |
CLI 命令行模式
# 显示所有模型排名
llmfit --cli
# 只看完美适配的模型,前5个
llmfit fit --perfect -n 5
# 查看系统配置
llmfit system
# 搜索模型
llmfit search "llama 8b"
# 查看单个模型详情
llmfit info "Mistral-7B"
# 获取推荐(JSON格式,方便脚本调用)
llmfit recommend --json --limit 5
# 按用途筛选
llmfit recommend --use-case coding --limit 3
# 规划硬件需求
llmfit plan "Qwen/Qwen3-4B-MLX-4bit" --context 8192
REST API 模式
llmfit serve --host 0.0.0.0 --port 8787
启动后可以通过 HTTP 接口查询,适合集成到集群调度系统中。
核心功能
1. 硬件检测
支持多种 GPU:
| 厂商 | 检测方式 |
|---|---|
| NVIDIA | nvidia-smi |
| AMD | rocm-smi |
| Intel Arc | sysfs/lspci |
| Apple Silicon | system_profiler(统一内存) |
| 华为昇腾 | npu-smi |
2. 多维度评分
每个模型从四个维度评分(0-100):
- 质量:参数量、模型声誉、量化损失
- 速度:基于后端、参数量、量化的预估 tokens/sec
- 适配:内存利用率(最佳区间 50-80%)
- 上下文:上下文窗口能力
不同用途权重不同,比如聊天场景速度权重高,推理场景质量权重高。
3. 动态量化选择
不是假设固定量化级别,而是从 Q8_0(最佳质量)到 Q2_K(最省内存)自动尝试,选择能在你硬件上运行的最高质量级别。
4. MoE 架构支持
自动识别混合专家模型(如 Mixtral、DeepSeek-V3),因为每次只激活部分专家,实际显存需求比参数总量少很多。
5. 运行时集成
支持三种本地运行时:
- Ollama:自动检测已安装模型,支持直接下载
- llama.cpp:GGUF 格式下载
- MLX:Apple Silicon 专用
运行模式与适配等级
运行模式:
- GPU:模型完全装入显存,最快
- MoE:活跃专家在显存,非活跃在内存
- CPU+GPU:显存不够,部分用内存
- CPU:纯 CPU 运行
适配等级:
- Perfect:完美适配,GPU 加速
- Good:良好,有空间余量
- Marginal:勉强,或纯 CPU
- Too Tight:跑不了
实用技巧
手动指定显存
如果自动检测失败:
llmfit --memory=24G
限制上下文长度
llmfit --max-context 8192
连接远程 Ollama
OLLAMA_HOST="http://192.168.1.100:11434" llmfit
总结
llmfit 解决了本地运行 LLM 最头疼的问题:选模型。不用再查各种 benchmark、纠结量化级别,一个命令就知道你的机器能跑什么、怎么跑最快。
对于想尝试本地 LLM 但不确定硬件是否够用的朋友,强烈推荐试试这个工具。